Generative artificial intelligence (Generative AI)Generative artificial intelligence (Generative AI) is a type of AI that can create new content and ideas, such as conversations, stories, images, videos, and music. AI technologies attempt to mimic human intelligence in new computing tasks such as image recognition, natural language processing (NLP), and translation. Recently, Google introduced a new Large Language Model (LLM) artificial intelligence (AI) tool that can generate videos. On the 20th (local time), foreign media such as VentureBeat, an IT media outlet, reported that Google Research has unveiled 'VideoPoet', which creates videos based on text input. Not only can you create a video according to the text description, but you can also convert a static image to a dynamic image or change the video to your desired style. The explanation is that various types of videos can be created, from short films to music videos and explanation videos. Videopoet is a large-scale language model trained based on massive text and video data sets. Therefore, you can not only understand the relationship between text and video, but also create consistent and visually attractive videos. In particular, its ability to create consistent motion in long videos is also a strength. This model stitches together short video clips to create videos that are several minutes long. This means that it becomes possible to produce more complex and nuanced videos. Source: AI Post (AIPOST) (http://www.aipostkorea.com)  Generative AI is transforming the content creation industry and breathing new life into unimaginable stories and ideas. But on the other hand, video creation is becoming easier due to rapidly evolving AI tools. There are also concerns that there will be a lot of ‘fake’ or ‘hate’ content. ‘Open AI,’ an American company that developed ChatGPT, a generative artificial intelligence (AI), is expected to further accelerate development competition by unveiling a new generative AI that creates videos from sentences. 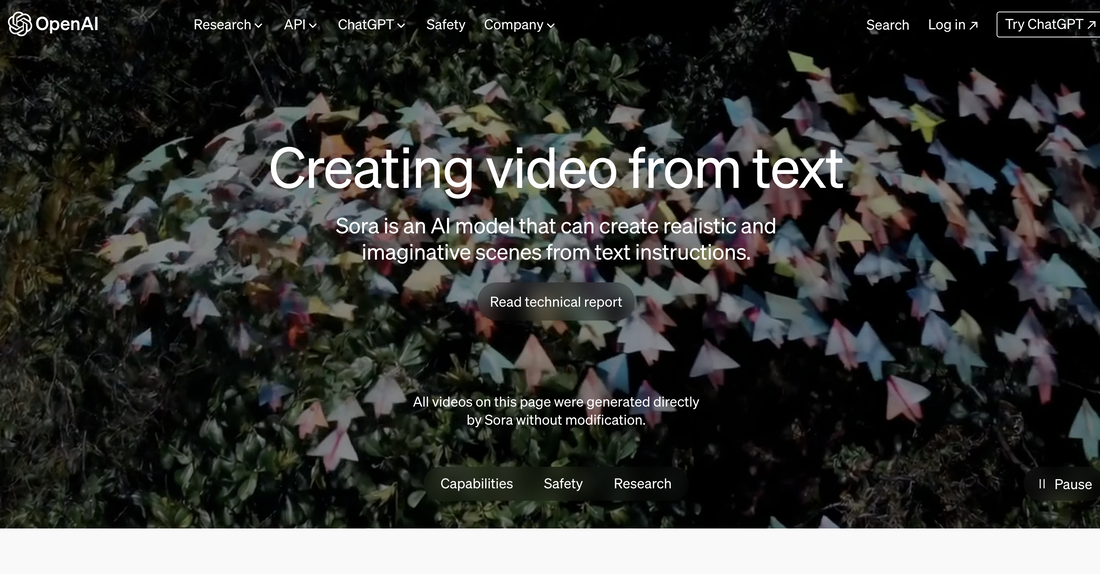 https://openai.com/sora  https://cdn.openai.com/sora/videos/art-museum.mp4  Sora can create complex scenes with multiple characters, specific types of actions, and precise details of subjects and backgrounds, and the model understands not only what the user requests in the prompt, but how this exists in the real world. The company also says that the model has a deep understanding of language, allowing it to accurately interpret prompts and create compelling characters that express vivid emotions, as well as multiple scenes within a single generated video that accurately maintain the character and visual style. He explained that it could be made.  As an example, I tried to use it by Invideo Ai as below: 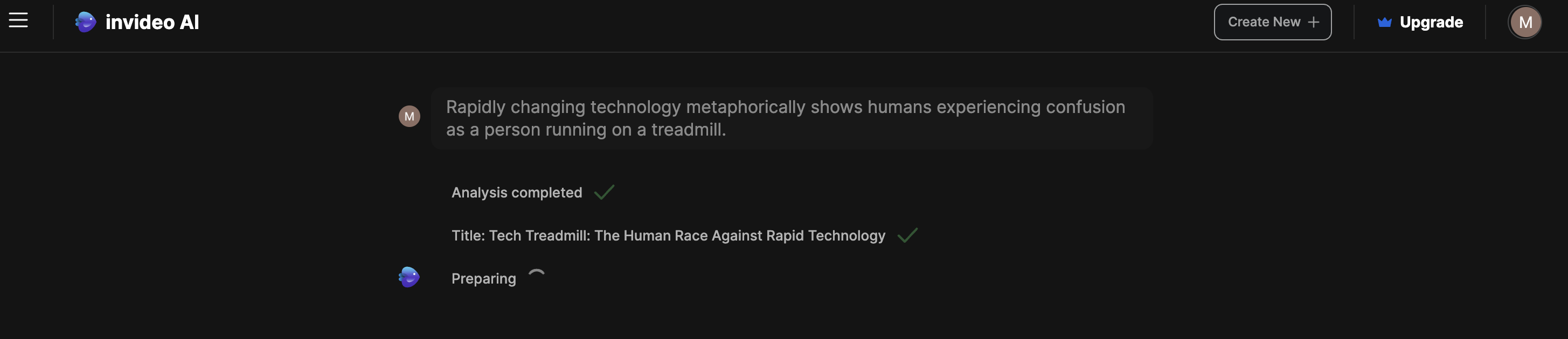 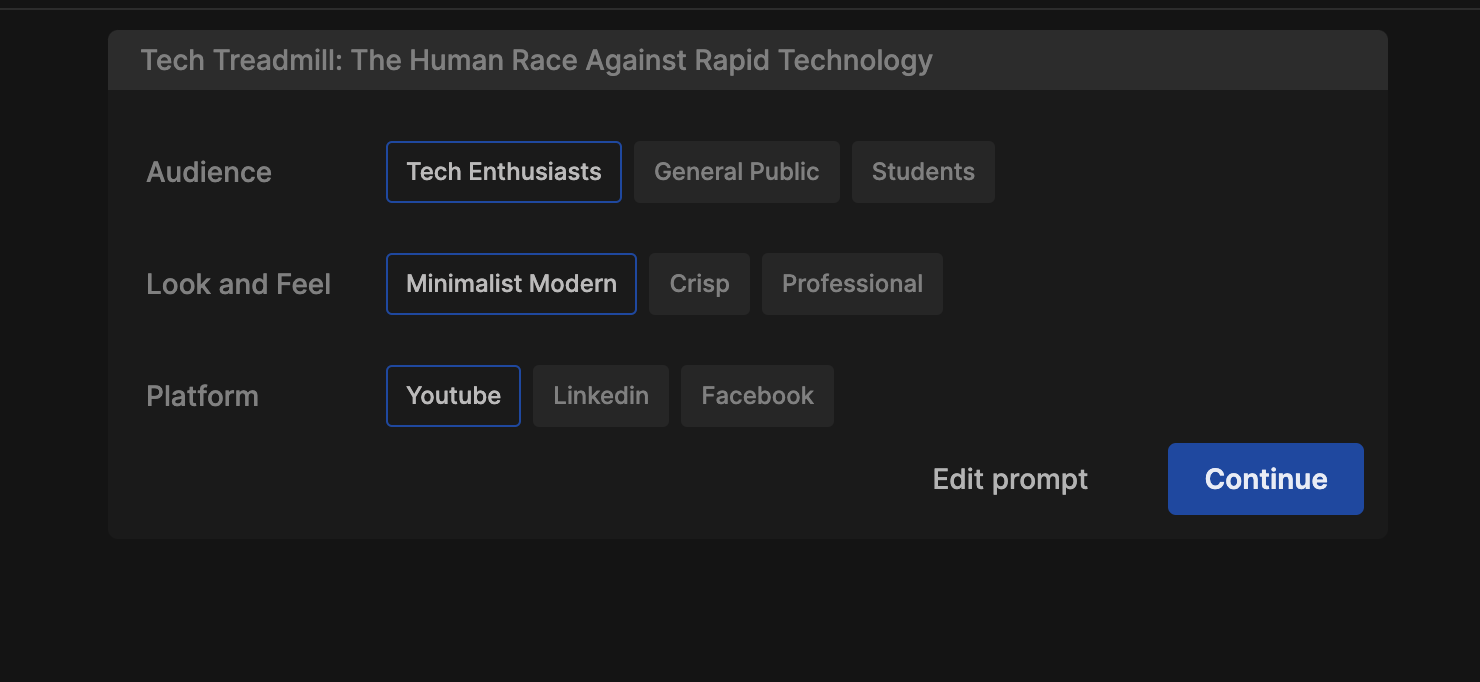 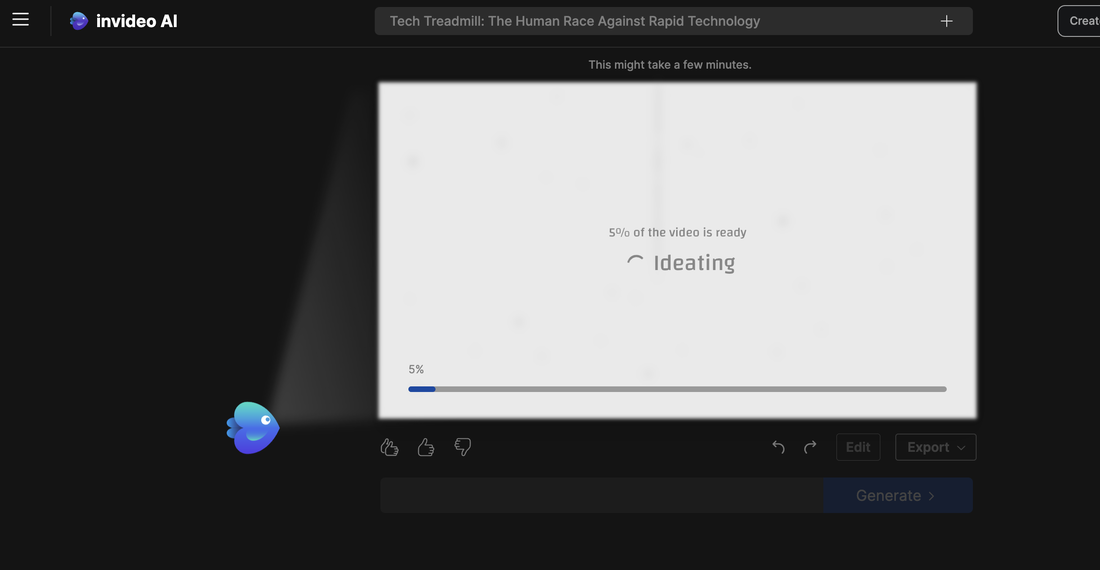 
0 Comments
Leave a Reply. |
Myungja Anna KohArtist Categories
All
Archives
July 2024
|

|
Blog for visual thinkers and artists ... |
 RSS Feed
RSS Feed